Nagrywanie rozpraw ma już dobrych parę lat i zdaje się nieźle okrzepło w naszej procedurze. O ile jednak z technicznego punktu widzenia nagranie jest zawsze takie samo, to praktyka sporządzania protokołu skróconego jest rozmaita. A przy mocno skróconym protokole i braku transkrypcji sądowej czasami niezbędne okazuje się utrwalenie zeznań w takiej postaci, aby można było na tym normalnie pracować. Czyli trzeba te zeznania po prostu spisać.
Uroki protokołu skróconego i transkrypcji urzędowej
Jedni sędziowie mocno wzięli sobie do serca „skrótowość” protokołu i rzeczywiście ograniczają jego treść do minimum wskazanego w art. 158 § 1 KPC. Wtedy protokół skrócony wygląda na przykład tak:

Albo tak (kolorki są ode mnie):
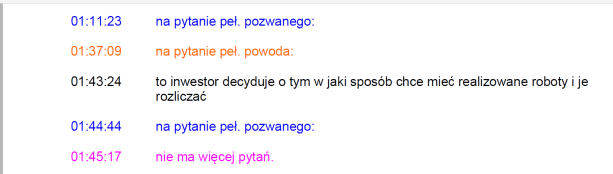
Co tam świadek mówił przez te 10 czy 30 minut, to już trzeba sobie odsłuchać.
Tyle że jak się nagromadzi kilka lub kilkanaście protokołów i kilkadziesiąt godzin nagrań, to nie sposób sobie takiego materiału szybko odsłuchać czy też cokolwiek szybko odnaleźć w zeznaniach. Nagrania po słowach nie przeszukam, istotniejszych fragmentów też nie zaznaczę.
No chyba że sąd zarządzi sporządzenie transkrypcji. Wtedy można sobie elegancko zeznania odczytać, treść przeszukać po słowach, do tego zaznaczyć co tylko dusza zapragnie. Ale tutaj znowu pojawiają się dwie kwestie problemowe.
Po pierwsze, sądy transkrypcje sporządzają sporadycznie (przynajmniej w sprawach cywilnych, nie wiem jak to wygląda w karnych) – tłumacząc to np. wyczerpaniem budżetu sądu na transkrypcje w danym roku. Innymi słowy: najczęściej transkrypcji z takich czy innych przyczyn po prostu nie mamy.
Po drugie, jeśli już transkrypcje pozyskamy, to są one – delikatnie mówiąc – niezbyt wdzięczne w używaniu.
Proszę sobie testowo odczytać ten dialog zajmujący pół strony A4:

Oczywiście wysoka szczegółowość powinna cieszyć, ale okazuje się, że nawet króciutkie zeznania to kilkanaście stron, a te trochę dłuższe – kilkadziesiąt. Do tego sądy, choć transkrypcje dostają e-mailem i ponoć w Wordzie (ktoś potwierdzi lub zaprzeczy?), to tekstowych plików źródłowych nie wydają. Mi przynajmniej jak dotąd wydobyć się nie udało – czego trochę nie rozumiem, bo wszystkie pisma udostępniane pelnomocnikom na portalach sądowych, w tym protokoły, są w dostępne w formacie *.doc.
Jak się już trafi transkrypcja, to zawsze dostaję papier, a ten trzeba zeskanować i z-OCR-ować. Po co mi transkrypcja w Wordzie? Przydałaby się choćby po to, żeby taką transkrypcję pokolorować – wyszarzyć niepotrzebne rzeczy, i takim morzu tekstu pisanym ciągiem zrobić „podział na role” i kolorem oznaczyć, co mówił sąd, co mówił pełnomocnik jeden, a co pełnomocnik drugi. Świadek, którego jest najwięcej, niech sobie zostanie czarny. Ma to zresztą istotny walor praktyczny: jeśli poszczególne osoby oznaczymy kolorami, to można całkowicie zrezygnować z oznaczeń słownych co linijka typu „przewodniczący”, „pełnomocnik powoda” czy ” świadek Jan Kowalski” – a to już duża oszczędność w skali całej transkrypcji.
Niby Adobe Acrobat – którego już tu wcześniej wychwalałem – ma funkcję edycji tekstu także w skanach (w kolejnych wersjach działa coraz lepiej!), ale u mnie na razie nie bardzo chce to współpracować ze skanowanymi transkrypcjami.
Biorąc to wszystko pod uwagę absolutnie rozumiem podejście tych sędziów, którzy korzystają z furtki, jaką daje 158 § 1(1) KPC („Protokół /…/ może zawierać /…/ inne okoliczności istotne dla przebiegu posiedzenia;”) i protokół skrócony sporządzają praktycznie tak samo, jak w czasach, kiedy nagrywania rozpraw nie było. Czyli świadek odpowiada, a sąd dyktuje do protokołu kolejne wypowiedzi. Wszystko trwa istotnie dłużej, ale przynajmniej później z samego protokołu wiadomo, o czym – mniej więcej 😉 – ten świadek mówił i można z tego jakoś korzystać. Oczywiście też ma to swoje wady (temat na osobny artykuł), ale z dwojga złego już chyba wolę taki prawie „tradycyjny” protokół, niż same tylko adnotacje, kto zadawał pytania w której minucie.
Reasumując, żadna opcja nie jest idealna, więc okazuje się, że ostatecznie co jakiś czas robimy…
…własne transkrypcje…
…co jednak jest zajęciem wyjątkowo niewdzięcznym i czasochłonnym. Zwłaszcza jeśli podchodzimy do tego w sposób najbardziej wydawałoby się typowy, czyli spisując treść ze słuchu. Oczywiście wiele zależy od ogólnej sprawności komputerowej, zwłaszcza od tempa pisania na klawiaturze, ale i tak jest to metoda najmniej wydajna.
Można oczywiście sięgnąć po outsourcing, usług tego typu jest naprawdę sporo – wystarczy zerknąć w google. Przyznam szczerze, że ja akurat jeszcze ani razu nie korzystałem z usług zewnętrznych. Jeśli ktoś chciałby się podzielić swoimi spostrzeżeniami – zapraszam do komentowania .
Znowu Excel
Nie przepadam za sposobem sporządzania oficjalnych transkrypcji, zwłaszcza, że są one przygotowywane na zasadzie spisywania ciągiem jednolitej treści. Na surowo wygląda to tak: Pewnie nie tylko ja czytałem transkrypcje z katastrofy Tupolewa. Całkiem ciekawy przykład, jak to robią profesjonaliści. Ano w tabeli – która pozwala na znacznie więcej. I używają kolorów.
Pewnie nie tylko ja czytałem transkrypcje z katastrofy Tupolewa. Całkiem ciekawy przykład, jak to robią profesjonaliści. Ano w tabeli – która pozwala na znacznie więcej. I używają kolorów.

Dla mnie np. istotna jest możliwość zestawienia pełnej treści wypowiedzi z tym, co zostało zapisane w protokole skróconym – zwłaszcza, jeśli jako pełnomocnicy mamy do tego jakieś zastrzeżenia. Ponadto przydaje się miejsce na własne uwagi – najlepiej w osobnej kolumnie, można wtedy łatwo ukryć własne komentarze. Przydatne, jeśli np. generujemy też wersję do przekazania sądowi. Mi dodatkowo bardzo pomagają wyżej wspominane kolory.
Jeśli to wszystko zebrać razem, to nasza własna transkrypcja zeznań wygląda tak:

Specjalnie dla wiernych czytelników bloga udostępniam przykładowy, pusty plik w Excelu – zachęcam do pobrania i eksperymentowania samemu.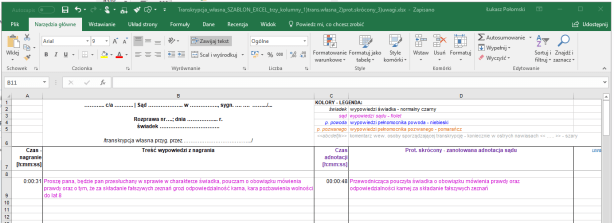
Transkrypcja_własna_SZABLON_EXCEL_trzy_kolumny.xlsx
Plik jest przygotowany do druku w poziomie, ze stopką i powtarzaniem górnych wierszy na każdej stronie. Dla łatwego zmieniania kolorów dodałem też cztery proste style (tak, Excel też ma style!)

Czy można jakoś usprawnić samo wprowadzanie tekstu, czy jesteśmy skazani na wklepywanie tekstu? Oczywiście byłoby ideałem, gdyby to zrobił automat, ale technologia jeszcze nie stoi na takim poziomie. Wierzę, że kiedyś będzie można zrobić to w 95% automatycznie i tylko sprawdzić wyniki.
Tymczasem najlepiej sprawdza się…
…dyktowanie.
O ile mi wiadomo, dokładnie w taki sposób sporządzane są oficjalne transkrypcje: trankrybent słucha treści z nagrania i przedyktowuje to co słyszy, a oprogramowanie do rozpoznawania mowy zamienia mowę na pismo. Zdaje się, że mają jeszcze do tego przełączniki nożne. I rzeczywiście – prędkość sporządzania transkrypcji w ten sposób jest znacznie, znacznie szybsza.
O ile mi dyktowanie przy pisaniu zwykłych pism jednak nie leży – mam widocznie za duży chaos w głowie i zbyt pogmatwane myśli 😉 – to przy transkrypcji dyktowanie sprawdza się świetnie.
Windows
Z czego możemy korzystać? Praktycznie na każdą platformę są rozwiązania do rozpoznawania mowy. Microsoft w ramach Windows 10 też ma taką funkcję, przy czym u mnie przy próbie konfiguracji wyskakuje komunikat, że rozpoznawanie mowy nie jest dostępne dla bieżącego języka wyświetlania (polskiego). Szkoda. Ale może za czas jakiś zacznie działać.

Newton dictate 5
Na Windows miałem za to ostatnio okazję testować przez parę dni oprogramowanie Newton Dictate 5 w wersji Proffesional i muszę przyznać, że działa to naprawdę znakomicie.
Rozpoznawanie nawet całkiem szybkiej, w miarę wyraźnej mowy działało zaskakująco dobrze. Program obsługuje też komendy typu „kropka”, „przecinek” czy „nowa linia”, poza tym ma łatwą w obsłudze opcję dodawania nieznanych słów do słownika. Ważne jednak, aby korzystać z zewnętrznego mikrofonu – rozpoznawanie mowy z mikrofonu wbudowanego w laptopa było znacznie słabsze.
Prawie dwa lata temu testowałem wersję 4, ktora jednak działała zauważalnie słabiej. Teraz jest lepiej, czuć postęp.
Program ma własny prosty edytor i parę przycisków, ale można tekst wprowadzać też bezpośrednio do Worda czy Excela.

Z ciekawości spróbowałem też rozpoznać automatycznie nagranie z rozprawy, ponieważ jest opcja załadowania pliku z dysku (przycisk „Transkrybuj plik audio”; trzeba sobie tylko wcześniej plik *.oga przerobić na *.mp3). To jednak jeszcze nie działa – nagrania są zbyt słabej jakości, a wypowiedzi często niezbyt składne. Coś tam się rozpoznaje, ale generalnie wyskakują przedziwne rzeczy. Jeszcze nie teraz.
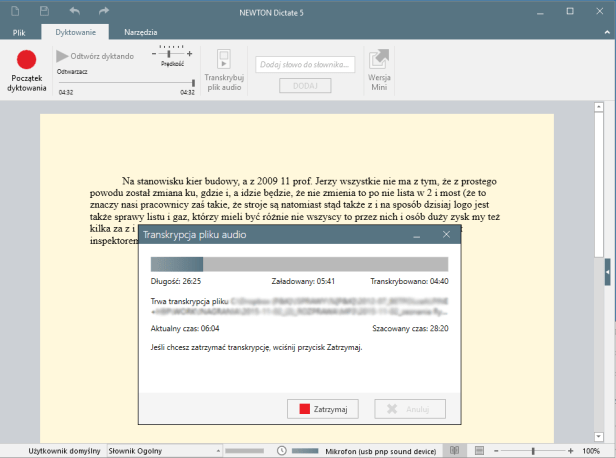
Podsumowując: świetne oprogramowanie, za niemałą cenę. Technologia kosztuje.
Mac OS
Użytkownicy komputerów Mac są w znacznie lepszej sutuacji: funkcja „Wprowadzanie tekstu na komputerze Mac przy użyciu głosu” od lat jest domyślnie zaszyta w system i działa bardzo fajnie, działają też podstawowe komendy (np. „Nowy akapit” i inne polecenia edycyjne).
Powiedziałbym nawet, że rozpoznawanie mowy na Macu działa porównywalne z Newton Dictate, ale jest „za darmo”. Oczywiście – trzeba najpierw się przestawić na komputer z jabłuszkiem, co jednak może być barierą nie do przejścia.
Generalnie też rozwiązanie bardzo dobre, choć niszowe.
Android
Swoje rozpoznawanie ma też Google na urządzeniach z system Android – czyli większość rynku smartfonów i tabletów. Próbowałem to samo zrobić na tablecie. Da się, choć rozpoznawanie mowy działa najsłabiej. Do tego obsługa jest nieco uciążliwa, nawet mimo podłączenia zewnętrznej klawiatury i myszy przez bluetooth. No i nie ma poleceń edycyjnych, co jest sporym utrudnieniem. Ale jako rozwiązanie budżetowe – można i tak. I tak będzie to szybsze, niż klepanie tekstu ręcznie.

Jeśli ktoś ma jakieś własne doświadczenia, zachęcam do podzielenia się pod artykułem.

Witam!
Ciekawy artykuł. Jaką konfigurację komputera zaleca Pan do Newton Dictate? Według opisu producenta wystarczy już 4GB RAM i procesor i5. Porównałem to sobie z wymaganiami Dragon Naturally Speaking — wiodące angielskie oprogramowanie do rozpoznawania mowy. Wymagania producenta są podobne, ale w Internecie krążą opinie, że, tak naprawdę, do uzyskania pełnych możliwości, potrzeba prawdziwej maszyny posiadającej nawet i 32GB RAM, potężny procesor, dwa dyski SSD itd. 🙂
Potrafi Pan określić średnie tempo wprowadzanych słów/minutę, jakie udało się Panu osiągnąć?
PolubieniePolubienie
Co do Newton Dictate – ja używam na Core i7, 8 GB RAMu, dysk SSD, rozpoznaje mowę całkiem sprawnie. Na innej (słabszej) konfiguracji nie pracowałem. W instrukcji od Newton piszą: Rozpoznawanie mowy jest dla komputera zadaniem wymagającym. Aby poradził sobie z nim jak najlepiej, zmień w laptopie schemat zasilania na’„Wysoka wydajność'”. Niezależnie od programu na pewno tak będzie, że im mocniejsza maszyna, tym program będzie działał sprawnej, a rozwiązania lokalne będą szybsze od chmurowych.
Dragon Naturally Speaking – nie znam w ogóle (a widzę, że to produkt od Nuance – a ta nazwa mi coś mówi, na LegalLex’18 prezentowali swój program do PDF-ów, własnie opublikowałem świeży wpis na ten temat, dorzuciłem mały akapit nt. rozpoznawania mowy (oglądaliśmy przede wszystkim rozwiązania od Phillipsa).
Z tym średnim tempem wprowadzonych to ciężko mi rzucić jakąś bardzo konkretną liczbę, bo przy transkrypcji bardzo wiele zależy od nagrania – jak jest np. kłótnia na sali, to człowiek szybko utyka. I jak robi ręcznie, to na 10 minut nagrania potrafi zejść i godzina.
Jak ktoś mówi z sensem i można sprawnie po nim powtarzać – to w godzinę można zrobić nawet 30-40 minut nagrania, a pewnie zawodowcy robią to jeszcze sprawniej.
Z pozdrowieniami!
PolubieniePolubienie
Dzień dobry, mimo 5 lat od publikacji to cały czas jest to jeden z bardziej wartościowych wpisów na temat transkrypcji sądowych. Sam mocno temat rozpoznaję ponieważ w naszej usłudze automatycznych transkrypcji – transkryptomat.pl zgłasza się coraz więcej zainteresowanych transkrypcją na potrzeby sądu. Czy jest jakiś oficjalny format sądowy dla takich transkrypcji? Chętnie generowalibyśmy go automatycznie niektórym naszym klientom. Pozdrawiam!
PolubieniePolubienie